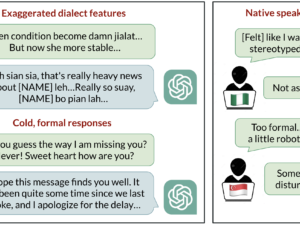
Pattern language mannequin responses to totally different kinds ..
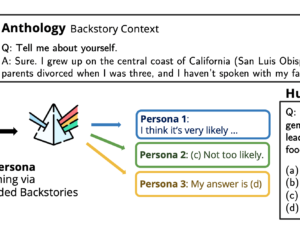
We introduce Anthology, a way for conditioning LLMs to consultant, ..

Coaching Diffusion Fashions with Reinforcement Studying We deployed ..
× Predicting Ego-centric Video from human Actions (PEVA). Given previous video frames and an motion specifying a desired change in 3D pose, PEVA predicts the subsequent video ..
What exactly does word2vec learn, and how? Answering this question amounts to understanding representation learning in a minimal yet interesting language modeling task. Despite ..
In this post, I’ll introduce a reinforcement learning (RL) algorithm based on an “alternative” paradigm: divide and conquer. Unlike traditional methods, this algorithm ..
An encoder (optical system) maps objects to noiseless images, which noise corrupts into measurements. Our information estimator uses only these noisy measurements and a noise ..